The basis for effective machine learning models
Optimize your Data: Insights into CONiX Data Processing
Ensuring data quality is essential for effectively training machine learning models. Without a comprehensive understanding of data quality, decisions about what data to use for testing, training and validation become intimidating. For instance, a neural network may experience decreased performance unexpectedly, necessitating the selection of more relevant scenarios to enhance data quality and improve network performance.
Why you need CONiX Data Processing
It provides multi-faceted solutions. First, our years of expertise and core intellectual property in data annotation ensure precise specifications for campaign-specific data, eliminating redundancies and ensuring data accuracy. Second, our priority is to enhance the quality of the data annotations by optimally aligning them with the desired ground truth data.
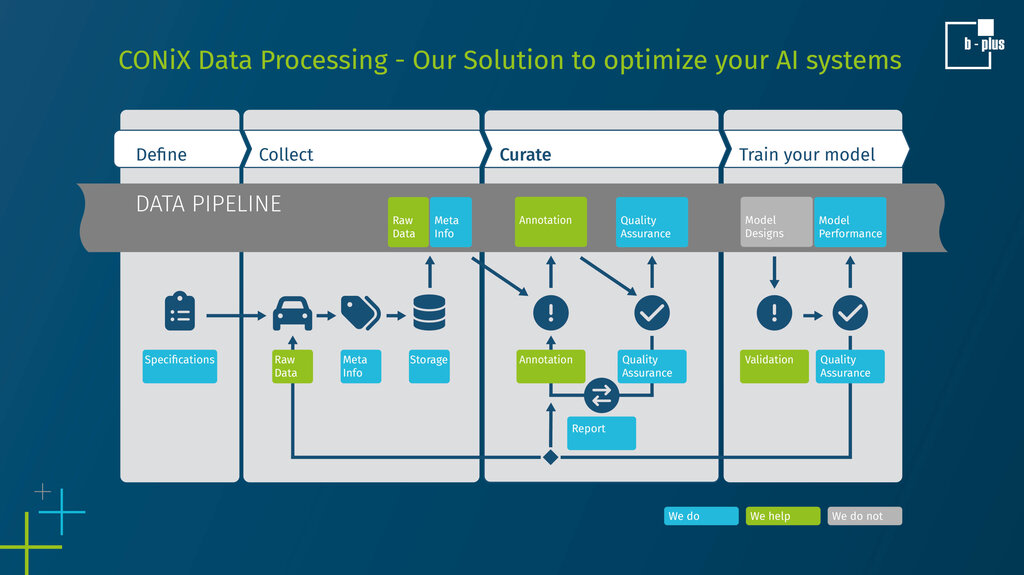
Our proven data processing workflow to optimize your data set:
1. Define
We place the customer at the center of our efforts, collaborating from the start to meticulously design requirements, including defining the use case, the operational design domain, jointly specifying concrete classes, and determining the optimal sensor setups for data generation. Moreover, although often overlooked, calibration is critical, as its neglect can lead to significant challenges during model training and restrict the future utility of the data.
2. Collect
We support the data collection process with our high-precision measurement equipment, gathering raw data and enriching the dataset with meta-information such as anonymization and tags. Additionally, we provide interfaces that allow the integration of custom services or algorithms provided by the customer, ensuring a diverse and comprehensive dataset tailored to specific needs.
3. Curate
During the curation phase, we align the data with state-of-the-art formats and best practices while ensuring compliance with predefined quality targets, specifications and annotation guidelines. Our robust hybrid quality assurance process leverages statistical analyses, computer vision and ML-based algorithms to pinpoint issues. Trained experts are seamlessly integrated to validate complex multi-sensor data, enhancing the process with automated QA insights. This strategy ensures high throughput and outstanding quality. After curation, the data is sent back to the client's server, where continuous feedback loops promote further dataset refinement and enhancement. Additionally, we provide detailed insights into the data content and QA process, offering our customers complete control over the data through comprehensive statistics, reports, benchmarks and quality metrics.
4. Train your model
Another key feature of our approach is its adaptability for model evaluation. We can handle annotations from both labeling companies and the customers' own models. During the evaluation phase, we provide the customer with detailed insights into the model's performance, identifying specific strengths and weaknesses. This valuable feedback helps refine specifications, metrics, and the data curation process itself, enhancing overall model effectiveness.
Our solution guarantees the highest quality datasets, which in turn power more effective machine learning models. This unmatched accuracy enhances efficiency and yields significant cost savings by targeting labeling efforts on critical dataset improvements. Training AI models with this refined data not only accelerates development cycles but also fosters innovation. Additionally, our transparent evaluation process provides customers with independent assessments, instilling confidence throughout the entire process. This represents a significant advantage over our competitors, setting us apart in the field.
Follow CONiX Data Processing Solution (b-plus.com) to learn more about CONiX Data Processing.