Die Basis für effektive Machine Learning Modelle
Optimieren Sie Ihre Daten: Einblicke in CONiX Data Processing
Die Sicherstellung der Datenqualität ist für ein effektives Training von Machine Learning Modellen unerlässlich. Ohne ein umfassendes Verständnis der Datenqualität wird es schwierig, zu entscheiden, welche Daten für Tests, Training und Validierung verwendet werden sollen. Ein Neuronales Netzwerk kann beispielsweise unerwartet schlechte Ergebnisse liefern, was durch die Verbesserung der Datenqualität oder die Auswahl relevanterer Szenarien verbessert werden kann.
Warum Sie CONiX Data Processing benötigen
CONiX Data Processing bietet vielfältige Ansatzpunkte, um das perfekte Datenset zu generieren. Erstens sorgt unsere jahrelange Erfahrung im Bereich der Datenverarbeitung für ML-Applikationen für die richtige Grundlage, nämlich anwendungsspezifische Spezifikationen. Im Bereich Datenselektion hilft CONiX Data Processing sowohl beim Aufzeichnen relevanter Daten als auch bei der Selektion der richtigen Subdatensätze. Dadurch werden Redundanzen eliminiert und die Eignung für den Use Case gewährleistet. Zweitens legen wir höchsten Wert auf die Qualität der Datenannotation. Dazu setzen wir unseren bewährten QA-Prozess ein, der Fehlerfreiheit garantiert, und nutzen unser QA-Tool, das für maximale Effizienz sorgt.
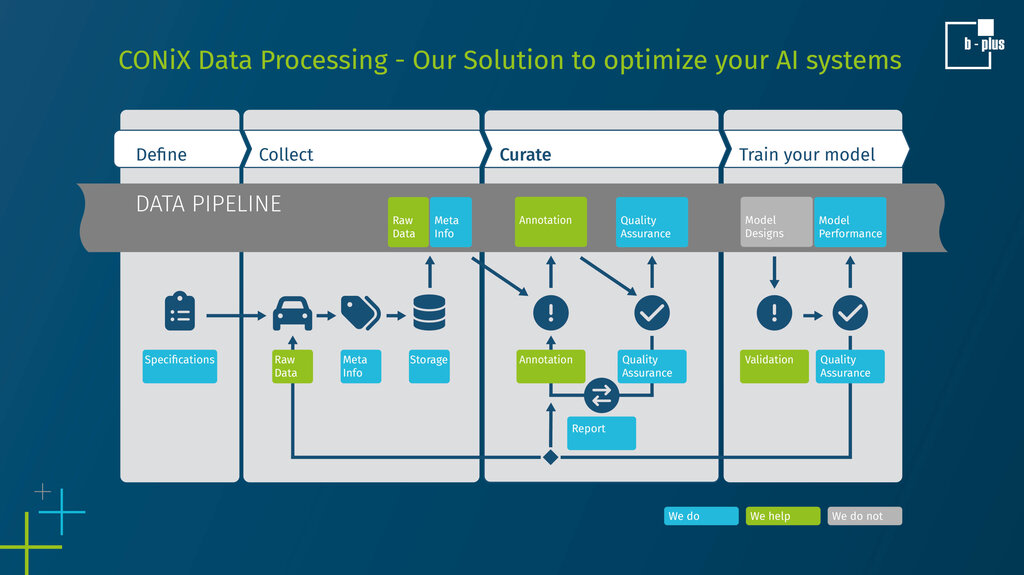
Unser Datenverarbeitungs-Workflow zur Optimierung Ihres Datensatzes:
1. Kundenorientiert definieren
Wir stellen den Kunden in den Mittelpunkt und arbeiten von Anfang an eng mit ihm zusammen, um seine Anforderungen präzise zu definieren. Dies beinhaltet die Festlegung des Anwendungsfalls, den operativen Anwendungsbereich, die Konkretisierung spezifischer Kriterien sowie die Bestimmung optimaler Sensoreinstellungen zur Datenerzeugung. Die Bedeutung dieses Prozesses wird oft unterschätzt, da eine Nichtbeachtung zu erheblichen Problemen in Bezug auf Datenkonsistenz und Sensorfusion führen sowie den zukünftigen Nutzen der Daten einschränken kann.
2. Rohdaten sammeln
Wir optimieren den Datenerfassungsprozess mit unseren hochpräzisen und zeitsynchronen Messgeräten und ergänzen den Datensatz mit Metainformationen, die sowohl zur Anonymisierung als auch zum Vorlabeln genutzt werden können. Zusätzlich bieten wir Schnittstellen an, die die nahtlose Integration kundenspezifischer Anwendungen oder Algorithmen ermöglichen. Auf diese Weise entsteht ein breit gefächerter und detailreicher Datensatz, der exakt auf individuelle Bedürfnisse zugeschnitten ist.
3. Qualitätssicherung der Daten
Wir optimieren die Daten gemäß den neuesten Standards und bewährten Verfahren, um effizient sicherzustellen, dass sie den vordefinierten Qualitätszielen, Spezifikationen und Annotationsrichtlinien entsprechen. Unser robuster hybrider Qualitätssicherungsprozess verwendet statistische Analysen, klassische Algorithmik und ML-basierte Verfahren, um Fehler in den Daten zu identifizieren und zu lösen. Geschulte Experten integrieren sich nahtlos in unsere Tool-Landschaft, um auch die komplexesten Multisensordaten zu validieren und die Datenqualität in einem ersten Schritt zu ermitteln, sowie später durch kontinuierliche Feedbackschleifen sicherzustellen. Diese Strategie gewährleistet hohe Durchsatzraten und erstklassige Qualität. Darüber hinaus bieten wir unseren Kunden detaillierte Einblicke in den Dateninhalt. Dies geschieht durch umfassende Statistiken, Berichte, Benchmarks und Qualitätsmetriken, um den Kunden einen transparenten Einblick in die Daten zu geben.
4. Trainieren Sie Ihr Modell
Ein weiteres Hauptmerkmal unseres Ansatzes ist seine Anpassungsfähigkeit. Wir sind in der Lage, die Qualität der Daten und ihrer Metainformationen auf eine nachvollziehbare und transparente Weise zu bewerten, unabhängig davon, ob diese Metadaten manuell erstellt, automatisch generiert, synthetisch erzeugt oder das Ergebnis von KI-Modellen sind. Bei der Analyse von KPIs, beispielsweise im Zusammenhang mit KI-Funktionen, bieten wir unseren Kunden detaillierte Einblicke in die Leistung der Modelle und zeigen spezifische Stärken und Schwächen auf. Dieses wertvolle Feedback unterstützt die Feinabstimmung der Spezifikationen, die Datenerfassung und den Datenkuratierungsprozess, was letztendlich zu einer Verbesserung der Gesamteffektivität des Modells führt.
Unsere Lösung gewährleistet Datensätze höchster Qualität, die wiederum die Entwicklung effektiverer ML-Anwendungen ermöglichen. Diese unerreichte Genauigkeit steigert die Effizienz und führt zu erheblichen Kosteneinsparungen, indem der Fokus auf die entscheidenden Einflussfaktoren bei der Erstellung hochwertiger Datensätze gelegt wird. Das beschleunigt nicht nur die Entwicklungszyklen, sondern fördert auch die Innovation. Darüber hinaus bietet unser transparenter Bewertungsprozess den Kunden unabhängige Einschätzungen, die während des gesamten Prozesses Vertrauen schaffen. Dieser Aspekt ist ein entscheidender Vorteil gegenüber unseren Mitbewerbern und positioniert uns als vertrauenswürdigen Partner in der Branche. Füllen Sie die Lücke, die Mitbewerber mit hochwertigen Daten haben und verschaffen Sie sich einen Wettbewerbsvorteil gegenüber Konkurrenten, die noch immer versuchen, durch Quantität statt Qualität zu überzeugen.
Erfahren Sie mehr über CONiX Data Processing: https://www.b-plus.com/de/portfolio/cloud-based-datenmanagement/data-processing-software-conix-dpc